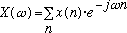 (1)
(1)This paper describes a system for audio analysis, modification, and synthesis, based on the Short Time Fourier Transform (STFT). The system is intended both as a tool for sound manipulation, and as a means to reinforce people's intuitions regarding the relationships between timbre and the harmonic structure of music and other audio signals, as conveyed via their spectrograms. This is done by creating a 3D spectrogram which shows a sound's harmonic structure in great detail as it is sampled. Similar systems in the past (for example, David Shipman's SPIRE system [1] [2]) have often sought to convey harmonic structure via two-dimensional spectrograms, sometimes in conjunction with wave form or other displays. By adding the third dimension (amplitude in dB mapped to surface height), it is hoped that a greater apprehension of the detailed structure can be achieved.
In order to use the system for both analysis and eventual resynthesis, a number of constraints must be satisfied which depend on the particular situation. Theses are discussed in the context of theory of the STFT in the first section.
The frequency domain is very useful for performing certain types of filtering operations. Due to the convolution theorem of the Fourier Transform, the time-domain convolution required for filtering can be performed more efficiently using the frequency domain equivalent of multiplication. The second section of this paper discusses some of the restrictions on the signal and filter in order to achieve the desired result. It then details several techniques for spectral modifications, including cross-synthesis, Formant Wave Function (FOF) filtering, and spectral envelope filtering.
The third section discusses the particulars of the spectrogram program itself, including the computing environment, the user interface, and the various features for analysis and spectral modification.
The fourth section presents some sound examples, demonstrating the capabilities of the system.
The last section summarizes the results and discusses possibilities for future work.
In some ways, the human auditory system functions as a spectrum analyzer, decomposing incoming pressure signals into their constituent frequencies via the space-frequency transfer function of the cochlea [3]. As a result of this, such frequency domain, or spectral representations have found wide application in the analysis and synthesis of sounds for musical and voice/telephony applications. Most of these methods are based on the Fourier Transform, which for discrete time signals is given by the following formula, known as the Discrete Time Fourier Transform (DTFT):
(1)
The original sequence
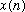 can be recovered by using the inversion formula:
can be recovered by using the inversion formula:
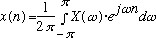 (2)
(2)
If
is time-limited to a duration of N samples, then we can sample the continuous
function
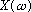 at N uniformly spaced points in the range
at N uniformly spaced points in the range
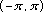 .
This corresponds
to forming a periodic signal
.
This corresponds
to forming a periodic signal
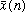 of infinite duration and period N by concatenating the length N sequences
(so-called `periodic extension') and computing its Fourier Series expansion.
This version of the Fourier Transform is written:
of infinite duration and period N by concatenating the length N sequences
(so-called `periodic extension') and computing its Fourier Series expansion.
This version of the Fourier Transform is written:
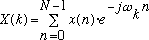 (3)
(3)
where
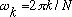 .
This expression is the Discrete Fourier Transform, or DFT, of the length N
discrete time sequence
.
Here, k is the DFT bin number, and
.
This expression is the Discrete Fourier Transform, or DFT, of the length N
discrete time sequence
.
Here, k is the DFT bin number, and
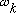 is the discrete frequency of bin k. If the sampling rate is
is the discrete frequency of bin k. If the sampling rate is
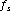 Hz, then the frequency of bin k in Hz is given by:
Hz, then the frequency of bin k in Hz is given by:
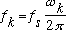 (4)
(4)
The corresponding Inverse Discrete Fourier Transform (IDFT) is given by:
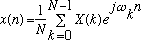 (5)
(5)
If
is
time-limited to a length N, then it can be recovered completely by taking the
IDFT of the N frequency samples.
DFT based analysis/synthesis methods are very prevalent in the signal processing literature, primarily due to the existence of Fast Fourier Transform (FFT) algorithms, which allow the computation of the DFT to be performed in O(N log N), rather than O(N2) computations.
In this chapter we present a particular Fourier based analysis method called
the Short Time Fourier Transform (STFT) [4] [5]. As stated above, the DFT
operates on finite length (length N) sequences. The STFT is a formulation that
can represent sequences of any length by breaking them into shorter blocks, or
frames, and applying the DFT to each block. Since we are using length N
DFTs, we must take the frame length M<=N. A frame is constructed by
multiplying the (possibly) infinite length sequence
by a length M window
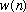 .
These resulting sequences of length M can now be represented completely by
length N DFTs.
.
These resulting sequences of length M can now be represented completely by
length N DFTs.
Let us define a length M windowed frame of data by:
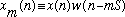
where S is the number of samples advanced between frames. The windowing operation for a given frame is illustrated in Figure 1.
Now define the fixed-time-origin sequence
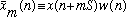
where
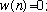
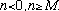
Figure 1. An example of how
is windowed to create
 .
.
Then we can define the DFT of
 :
:
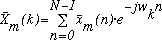
This expression, a function of discrete frequency index k, and frame index m,
is the STFT of
.
Thus, the STFT expresses a signal
as a series of DFTs of windowed frames of
.
Under certain conditions, the original sequence can be recovered from the
delayed and added sum of length N blocks, each of which is the result of an
IDFT of
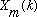 .
The equation which represents this is given by:
.
The equation which represents this is given by:
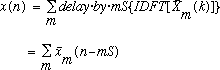 (6)
(6)
In the case where S<M, the individual frames will have overlapping data points. Hence, this method of signal reconstruction is often referred to as the Overlap-Add (OLA) method. In the following sections, we will discuss some of the issues surrounding the choice of various analysis parameters, including window length and type, FFT order, and stride.
The choice of the analysis window is important, since it directly affects the trade-off between frequency resolution and side-lobe attenuation, as seen below. Furthermore, the window function must satisfy certain constraints in order to guarantee that the original signal can be reconstructed from the STFT.
To understand the effect of the window, let us consider its effect on a complex
exponential, given by
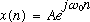 .
If we window this signal with a length M function
.
If we window this signal with a length M function
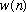 ,
and take its DTFT, we obtain:
,
and take its DTFT, we obtain:
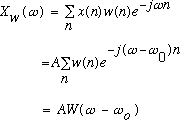 (7)
(7)
where
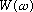 is the DTFT of the window. From this, we see that the
transform of a windowed sinusoid is the transform of the window function
shifted to be centered at the frequency of the sinusoid. The simplest window
function is the rectangular window, which has a DTFT given by:
is the DTFT of the window. From this, we see that the
transform of a windowed sinusoid is the transform of the window function
shifted to be centered at the frequency of the sinusoid. The simplest window
function is the rectangular window, which has a DTFT given by:
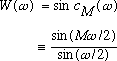 (8)
(8)
The width of the main lobe of this function is 2
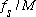 ,
as represented by the distance (in Hz) between the first two zero crossings of
the window transform. This corresponds to a width B of two bins of the DFT. The
height of the largest sidelobe is -13dB relative to the main lobe peak which is
rather poor for analysis, since this leads to cross talk between DFT bins. In
comparison, the Hamming window has a mainlobe width B=4 bins, but the largest
side lobe is at -43 dB relative to the main lobe. Harris [6] has documented the
tradeoff between mainlobe width and sidelobe suppression for most of the
commonly used windows. In this paper, a Hamming window is often used, since it
has the `sum to constant' property described below.
,
as represented by the distance (in Hz) between the first two zero crossings of
the window transform. This corresponds to a width B of two bins of the DFT. The
height of the largest sidelobe is -13dB relative to the main lobe peak which is
rather poor for analysis, since this leads to cross talk between DFT bins. In
comparison, the Hamming window has a mainlobe width B=4 bins, but the largest
side lobe is at -43 dB relative to the main lobe. Harris [6] has documented the
tradeoff between mainlobe width and sidelobe suppression for most of the
commonly used windows. In this paper, a Hamming window is often used, since it
has the `sum to constant' property described below.
If we wish to resolve two closely spaced sinusoids at frequencies f1 and f2, we
must assure that the main lobe is narrow enough that the two modulated window
transforms can be distinguished. This is not a requirement for reconstruction,
but can be important for visual analysis of the spectra or decomposition into
sinusoids [7]. In this case, we would, for example, require that the first
zero-crossings of the two modulated sinusoids fall at the midpoint between the
two center frequencies, as in Figure 1. If the minimum frequency separation we
need to resolve is f2-f1 =
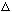 Hz, then we would require:
Hz, then we would require:
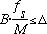
So, with a Hamming window, we require:
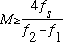
For harmonic signals, successive harmonics will be separated by f0, the
fundamental frequency of the analyzed signal. In this case, we would want
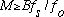 ,
or equivalently, B periods of the wave form should fall under one window.
,
or equivalently, B periods of the wave form should fall under one window.
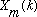 of this frame. The size, N, of this DFT must be at least M, with any additional
samples being produced via "zero-padding". There are several issues involved in
choosing a good value for N. First, in order to take advantage of the
computational efficiency of the FFT algorithm, we want to take N to be a power
of 2. Secondly, the visual display produced by the analysis will be represented
by N samples of the DTFT. The larger we make N, the closer the DFT will
approximate the smooth function of
of this frame. The size, N, of this DFT must be at least M, with any additional
samples being produced via "zero-padding". There are several issues involved in
choosing a good value for N. First, in order to take advantage of the
computational efficiency of the FFT algorithm, we want to take N to be a power
of 2. Secondly, the visual display produced by the analysis will be represented
by N samples of the DTFT. The larger we make N, the closer the DFT will
approximate the smooth function of
 represented by the DTFT. A value
that is too small, while not throwing away any information (N must be >= M),
will produce a very coarse visual display that may lead to misinterpretation of
the data. The last issue to be considered in choosing the FFT length is based
on the fact that we may modify the STFT before performing the resynthesis, as
discussed below. Since this corresponds to convolution by some finite length
impulse response in the time domain, which will lengthen the resulting
sequence, we must zero pad the windowed data by a sufficient amount to prevent
time-aliasing. This constraint is developed in the next chapter.
represented by the DTFT. A value
that is too small, while not throwing away any information (N must be >= M),
will produce a very coarse visual display that may lead to misinterpretation of
the data. The last issue to be considered in choosing the FFT length is based
on the fact that we may modify the STFT before performing the resynthesis, as
discussed below. Since this corresponds to convolution by some finite length
impulse response in the time domain, which will lengthen the resulting
sequence, we must zero pad the windowed data by a sufficient amount to prevent
time-aliasing. This constraint is developed in the next chapter.
At this point, we must decide how often an analysis frame will be computed. This decision is very application dependent. if the only goal is to create a visual representation of the signal, then the stride should be chosen by simply trading off temporal resolution for computation time. If the signal under analysis has rapid transients, such as percussive sounds, then an analysis frame may be require every millisecond or do, so as not to smooth out the transients. The cost for this approach is that the resulting data set will be very large and the time required to display this data will increase accordingly. on the other hand, if it is desired to represent only the long term evolution of a signal, as in analyzing an entire musical passage, for example, then it may suffice to perform an analysis on the time scale of the shortest event of interest, perhaps a note duration, which could be in the hundreds of milliseconds. If, however, the analysis is being performed with the ultimate goal of performing a resynthesis (with possible modifications), then there are more specific requirements. If perfect reconstruction of the input is required (from unmodified STFT data), the stride, S, must be such that the overlapped window functions sum to a constant over all n, as in:
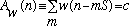 (9)
(9)
Figure 2 illustrates this requirement graphically. For the Hamming window, (9) can be satisfied by taking S=M/2j, j an integer.
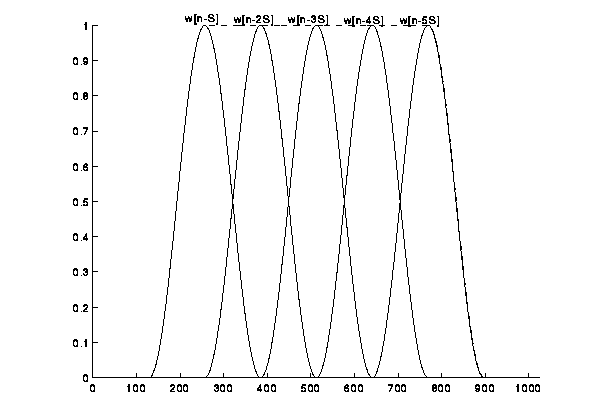
Figure 2. A window that overlaps and adds to a constant (1.0).
Given this constraint, then
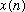 can be reconstructed by simply summing the IDFTs of the
can be reconstructed by simply summing the IDFTs of the
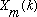 :
:
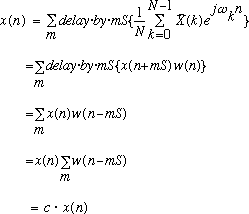 (10)
(10)
given (9). This overlap-add procedure is illustrated for a portion of a signal
in Figure 3. It should be mentioned that
can actually be reconstructed from
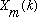 even without condition (9), provided that the analysis window never decays to
zero. After performing the overlap-add computation in (10), we will now have
modulated by some function formed by the overlapped windows. In this case,
can be recovered by dividing out this amplitude modulation. The only
requirement here is that each point of
falls under an equal number of analysis windows, which means that valid values
for S are given by S=M/j, where j is any integer that divides M with no
remainder.
even without condition (9), provided that the analysis window never decays to
zero. After performing the overlap-add computation in (10), we will now have
modulated by some function formed by the overlapped windows. In this case,
can be recovered by dividing out this amplitude modulation. The only
requirement here is that each point of
falls under an equal number of analysis windows, which means that valid values
for S are given by S=M/j, where j is any integer that divides M with no
remainder.
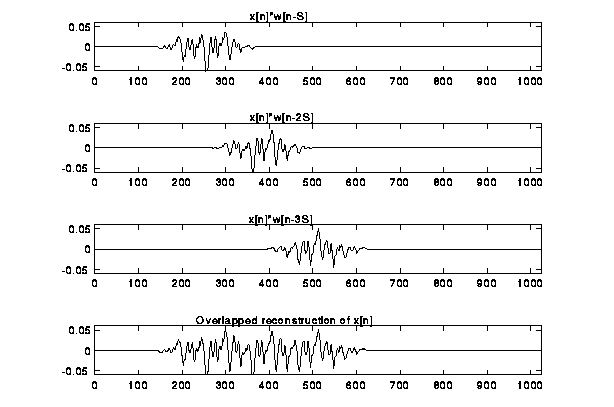 Figure 3. The overlap-add procedure showing the sum of 3 overlapping frames.
Figure 3. The overlap-add procedure showing the sum of 3 overlapping frames.
A more general form of reconstruction, called `weighted overlap-add' [8][9],
utilizes a `synthesis window',
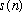 in the sum of STFT frames. In this case, condition (9) becomes:
in the sum of STFT frames. In this case, condition (9) becomes:
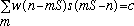 (11)
(11)
which says that the product of the analysis window and time-reversed synthesis window must overlap and add to a constant.
This extra level of windowing is required whenever modifications are made to
the STFT representation prior to synthesis. In this case, the individual frames
may no longer follow the envelope of the analysis window, so some form of
smoothing is needed. By post multiplying the IDFTs by
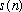 ,
discontinuities at the synthesis frame boundaries are removed.
,
discontinuities at the synthesis frame boundaries are removed.
A useful means of generating window pairs that satisfy (11) is to use the same window for both analysis and synthesis, and, choosing a symmetric window, we have:
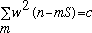
In this case, we can use a window that is the square root of a window having the sum-to-constant property, and the condition is satisfied. This is the approach used when spectral modifications are made using the present system. Other authors [10] have proposed similar schemes which are based on minimizing the squared error between the modified STFT and the STFT of the Inverse STFT. These are not always the same, since the STFT is redundant, therefore there are many (in fact, infinitely many) modified STFTs which are not STFTs of possible signals. In practice, the approach outlined here works well.
The STFT representation described in the previous section allows signal
modification in the frequency domain by altering the values of
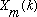 .
The most straightforward approach is to scale the bin magnitudes via some
frequency dependent filter function. This frequency domain multiplication
operation corresponds to convolution in the time domain. By changing the
functions which multiply
.
The most straightforward approach is to scale the bin magnitudes via some
frequency dependent filter function. This frequency domain multiplication
operation corresponds to convolution in the time domain. By changing the
functions which multiply
 over successive frames, time varying filtering operations can be performed on
the signal. As we will see in the following sections, useful filtering
operations can be efficiently performed in the way, provided certain important
constraints are satisfied.
over successive frames, time varying filtering operations can be performed on
the signal. As we will see in the following sections, useful filtering
operations can be efficiently performed in the way, provided certain important
constraints are satisfied.
Let use represent an arbitrary FIR filter by the sequence:
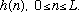
We can represent the filtering of a signal
by
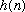 using the following equation:
using the following equation:
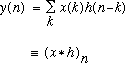 (12)
(12)
In the frequency domain, this can be written as:
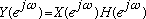
If the length of the filter is L and the length of
is P, the total length of the sequence
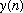 is L+P-1. The basic concept behind FFT based convolution methods is to break
into frames, as in the STFT, then perform a multiplication on the STFT frames,
and inverse transform the result. In order to produce a valid inverse transform
for
is L+P-1. The basic concept behind FFT based convolution methods is to break
into frames, as in the STFT, then perform a multiplication on the STFT frames,
and inverse transform the result. In order to produce a valid inverse transform
for
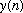 ,
we must make the FFT size long enough to prevent time-domain aliasing. This can
be guaranteed as long as the FFT size is greater than the maximum length of the
resulting convolution, or N>=L+P-1.
,
we must make the FFT size long enough to prevent time-domain aliasing. This can
be guaranteed as long as the FFT size is greater than the maximum length of the
resulting convolution, or N>=L+P-1.
If, on the other hand, this requirement is violated, the inverse STFT will still produce a sequence, but it will contain time-aliased components. The forward transform of this aliased sequence may not be the same as the modified STFT it was computed from. In this case, the modified STFT is not considered `valid' (although it may still by useful to work with).
One powerful application of the STFT representation is in modifying the
duration of an analyzed signal without changing its pitch. This is performed by
re-sampling the
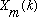 in time, using either linear or (preferably) band-limited interpolation to a
new time base, recomputing the phase information, then performing the
overlap-add resynthesis. As an example, consider the case where we wish to
scale an utterance up by two, so that it takes twice as long. In this case, we
would:
in time, using either linear or (preferably) band-limited interpolation to a
new time base, recomputing the phase information, then performing the
overlap-add resynthesis. As an example, consider the case where we wish to
scale an utterance up by two, so that it takes twice as long. In this case, we
would:
1) Compute a new set of
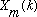 by interpolating magnitudes between pairs of the original
by interpolating magnitudes between pairs of the original
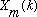 .
.
2) Double the phases of each FFT bin.
3) Take the IDFTs and overlap-add them at the original stride yielding the time stretched result.
Since the individual analysis frames will still produce the same frequency
information, the pitch contour of the original material will be preserved.
However, the evolution of the harmonic content will be spread out by the
interpolation factor (2 in the example). Step 2) is crucial: a sinusoid at
frequency
that is not at an exact multiple of
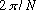 will have a
phase increment from analysis frame to analysis frame determined by:
will have a
phase increment from analysis frame to analysis frame determined by:
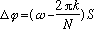
where k is the bin closest in frequency to
and S is the analysis
frame stride. If the synthesis frames are spread out to be gS samples apart,
the corresponding phase increment for that sinusoid must be corrected by the
same factor g. Typical analysis/synthesis systems [11] implement this phase
correction by first converting each bin from real/imaginary to magnitude/phase
representation (a polar to rectangular conversion), adding the phase
correction, and finally reconverting to real/imaginary representation prior to
the IDFT.
An even simpler model for phase has been suggested [12] where only the initial
phase information is kept, i.e. the phase of the first analysis frame. All
successive phases are computed by adding the time-scaling factor based
corrections to these initial phases. While this is computationally very
efficient, it has the side-effect of forcing the synthesized signal to be
purely harmonic at multiples of
.
In many cases, this effect will not
be objectionable.
Many useful modifications of the STFT can be performed by only altering the magnitudes of the bins, leaving the phase information unchanged. This corresponds to convolution with a filter having a zero-phase spectrum, which must therefore be an even function of time. These zero-phase filters are easier to implement, since they require only two multiplies/bin as opposed to four for the full complex multiplication necessary for an arbitrary phase filter. In addition to this inherent advantage, it is difficult to provide any intuitive description of how a particular phase modification (other than linear) will affect the resynthesized signal. Since the system we have implemented is designed to be intuitive, magnitude only modifications are the only ones implemented at this time. Given this restriction, there are still a wide range of interesting filtering operations that can be performed, as will now be shown.
Perhaps the easiest way to develop interesting filters is to use the magnitude spectrum of a signal which has already been analyzed as the filter. In this case, a so-called `source' sound is processed by convolving it with the magnitude spectrum of another so-called `filter' sound. This is a form of `cross synthesis', so named because the resulting signal has distinct characteristics from both of the original sounds. Note that the pitch of the resulting sound is that of the source sound, since the phase information of the result is taken directly from this sound. Examples of this technique are `vocoder' effects, where the filter sound is some vocal utterance, and the source is some instrumental sound having (preferably) a broad spectrum, such as strings. The result is a sort of `talking instrument' where the instrument sound has recognizable vocal articulations applied to it. Another form of cross-synthesis filtering, based on spectral envelopes, is discussed next.
A very useful decomposition of a signal is to model it as having been created
by some source signal
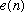 which has subsequently been filtered by some
,
as shown in Figure 4.
which has subsequently been filtered by some
,
as shown in Figure 4.
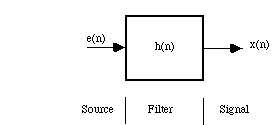
Figure 4. Source-filter signal model
These so-called `source-filter' models have the useful property that they have a separate representation for the pitch and harmonicity (e.g. voiced/unvoiced) information on the one hand, and timbral content (e.g. formant structure) on the other.
By applying the source component from one signal to the filter component of another, vocoder effects similar to the cross-synthesis technique described previously can be achieved. The difference is in how the filter signal is computed. In the above method, the STFT magnitude is used directly as the filter. In the spectral envelope method, a low order filter which somehow approximates the overall frequency structure of the filter sound is computed. Linear Predictive Coding (LPC) methods provide a simple and efficient means of computing low order filters that model the spectral envelope.
A program has been written to implement the FFT-based analysis/synthesis methods outlined above. This program is written in C, using the GL library for Silicon Graphics Indigo workstations. These machines have high-performance 3D graphics capabilities and built-in hardware for acquiring and playing back digital audio in real time.
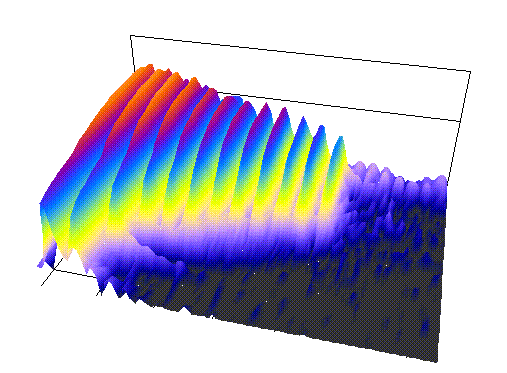
Figure 5. Spectral surface created from the analysis of a short trumpet note.
Once a surface has been created, the user can freeze it, by terminating the process of reading in new samples. At this point, the original wave form can be reconstructed by taking the ISTFT, as outlined above, subject to the constraints that were discussed. In addition, modifications may be made to the spectral surface prior to reconstructing the time-domain wave form, thus achieving the time-varying filtering effect. What follows is a description of the various elements of the spectrogram program.
The control panel for spectrogram is based on the FORMS tool [13], which allows
applications developers to easily create graphical user interface objects, such
as sliders, dialog boxes, and menus, via an interface builder. One simply grabs
the desired interface object from a list of available ones and drags it to the
desired place on the panel being designed. For each object, the programmer must
write a callback function which gets called by FORMS whenever that object is
manipulated by the user. Once all desired objects have been placed, one simply
says "Save Form", and a C program is generated which builds the appropriate
objects (in GL) and created the associations between the objects and their
respective callback functions. By linking this source file in with the
application program, all details of managing the user interface including
updating slider positions, etc., are handled by FORMS. The overall structure of
the various software modules is shown in Figure 6. The front panel used in
spectrogram is shown in Figure 7. In the following sections, reference will be
made to this figure.
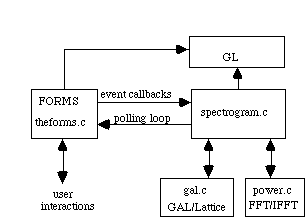
Figure 6. Overview of the spectrogram software environment.
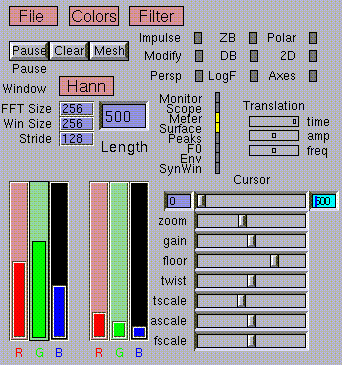
Figure 7. User interface of the spectrogram program.
The source for audio data can be either live audio from the ADC, or sample data from disk in the form of an AIFF (Audio Interchange File Format) File. This is selected via the File Menu. When opening a new file for input, a FORMS file-browser object is user to specify the file. For certain analysis parameters, e.g. when the stride is small, it may be necessary to drop out of real time operation. In this case, files are read, processed, and written, and the display is updated at a rate dependent on the analysis parameters.
Once audio is being acquired, one can adjust both the gain and the offset (in dB) of the spectral surface display. These two controls are very effective in achieving the best visual result for a given signal. For example, with a relatively high floor (low offset), only the highest peaks are displayed (all values below the threshold appear as a flat `floor'). If monitoring is enabled (via the `Monitor' button), the audio being analyzed is also played back through the DAC.
These parameters include FFT order, Window size, Stride, and Window Type. The first three correspond to N, M, and S in the above discussion. Whenever any of these is changed, it is necessary to re-analyze the audio data, so file input is recommended if the user is planning to experiment with these values. Then, one can change the parameters and see how the display is affected for a repeatable data source. The supported window types at this time are Blackman-Harris (4 types), Hanning, Hamming, Blackman, Exact Blackman, and Rectangular (no windowing).
It is also possible to specify whether or not to utilize a synthesis window. This choice is made via the Synwin button. A synthesis window should be used whenever significant modifications to the STFT are anticipated. When selected, the window function is recomputed to have an overlap-add sum to a constant for the squared window function.
During live input, data will be continuously analyzed and displayed as successive spectrogram slices until a predetermined number, specified by the Length parameter, have been processed. At this point, the display clears, and new slices start to be rendered at the t=0 position (normally in back). In file input mode, analysis continues until the end of the file, unless an overriding length is specified on the command line. In order to halt the ongoing analysis, the user must click on the Pause button, which puts the program in Pause mode, allowing the user to navigate around the spectral surface using a combination of mouse movements and sliders. The overall orientation is controlled using the middle mouse button. When this is depressed, left-right movement rotates the surface about a vertical axis through the center of the surface, and up-down movement rotates it about the t=N/2 horizontal axis where N is the total number of spectral slices. When the left mouse button is depressed, vertical movement zooms you toward or away from the surface.
To inspect the fine structure of the surface, the user can set the length parameter to examine only a small number of slices, and then scroll through the surface using the time cursor. This sets the starting time (slice) of the overall surface from which the subsection being examined will start. This cursor is only active in Pause mode, since in the Input modes, it is assumed the user will be computing a new STFT surface.
It is also possible to maneuver the surface laterally, using the `time', `freq', and `amp' translation slider. They move the center of the surface along the corresponding axes. Often times, it may be desirable to scale the surface in one or more directions. For example, the user may wish to increase the vertical height to examine a quiet section of the signal. Note that vertical scaling is not the same thing as input gain. As input gain is increased, the surface will get taller and brighter (assuming a gray scale color map). Vertical scaling on the other hand only affects the height. Scaling functions have been implemented in all three directions (freq, amp, time).
While in Pause mode, clicking the `Monitor' button makes it possible to hear the corresponding time-domain wave form, by reconstructing via inverse FFTs with Overlap-Added frames, assuming the restrictions on the analysis/synthesis parameters are obeyed. In addition, various modifications can be performed on the surface prior to reconstruction. Using the Filter menu, a time-varying filter can be loaded from disk, by opening the appropriate filter file in the file browser. This surface will multiply the surface of the analyzed signal on a point by point by point basis, whenever the Modify button is activated. When the result is played back, we hear the result of the modification. This result is also written to a file, in case the reconstruction cannot keep up with real time. Some of the sonic capabilities of these modifications will be discussed in the next chapter.
New filter files can be created by selecting Save under the Filter menu. This will compute the magnitude of the current surface at each point in the time-frequency plane, and write the results to the named file. For example, some vocal utterance may be analyzed and written to disk for subsequent use as a vocoder-like filter.
It is also possible to synthesize the filter surface directly, without having it multiply the current analysis data. This is done by clicking on the Source button, which will toggle between Impulse and Signal modes. When impulse is selected, the current analysis data is replaced by all ones, the transform of an impulse. This results in a synthesis which is the overlapped and added impulse responses of the current filter data. The pitch of the resulting sound will be determined directly by the stride, since that determines the spacing of the impulses applied to the time-varying filter. Clicking the Source button again reverts to modification (convolution) mode.
Aside from creating filters directly from the magnitudes of some analysis data, one can also create them from the spectral envelope of the analysis data. This is more appropriate when we want to only extract the overall spectral features (e.g. formant structure for vocal patterns) for subsequent filtering operations. The method used to compute the spectral envelopes is the Gradient Adaptive Lattice (GAL) algorithm [14], which is a form of LPC analysis. To cause this analysis to be carried out, the user clicks on the Env button. Again, the resulting formant-like surface can be stored to disk using the Filter menu.
Filters based on formant wave functions [15] can also be created. In order to do this, the user selects 2D mode (see below), and can then begin to draw filter trajectories using the mouse. The user must be in Pause mode, with Modify and Impulse source selected, in order to clearly see the filter functions being computed. Each time the left mouse button is pressed, a new point is entered for the current FOF trajectory. Successive points are joined by straight lines, which represent the evolution of this FOF's center frequency vs. time. The middle mouse button can be used to begin a new trajectory for the current FOF. In this way, one FOF may be turned on and off during the evolution of the surface. Once the current FOF is completely specified, the user can click with the right mouse button, which allows entering points for the next FOF trajectory, and so on, up to the total number of FOFs desired. At each spectral slice, the contributions of all FOFs active at that slice are summed to produce the composite filter to be used for that frame. A typical FOF based filter is shown in Figure 8.
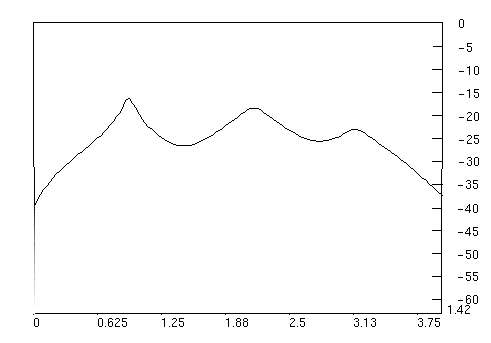
Figure 8. A typical multi-FOF filter frequency response.
The program has a number of flexible features which affect the appearance of the spectrogram on the screen. These will each be described briefly now.
The 256 entry color map, which initially maps 0 amplitude to black and full-scale to white, can be edited using the group of sliders on the lower left in two different ways. In Interpolate mode, the left 3 sliders control the 0 amplitude color, while the right three control the full-scale color, with intermediate values being interpolated linearly between these extremes. In SineColors mode, the left three determine the phase and the right 3 determine the frequency of three independent sinusoidal chrominance gratings, one for each of Red, Green, and Blue. The mode is determined in the Map menu. This menu also allows the user to save and load color maps to/from disk, again via file browsers. In all cases, color index 0 is fixed to give a black background, and color index 255 is fixed to give white axes and labels. A log frequency scaling option has been implemented, which plots the spectrogram as a function of linear time and log frequency. This mode, invoked via the LogF button, may facilitate visual analysis of low-frequency detail, since it has the effect of stretching out the lower bins of the FFT.
It is possible to defeat the axis labels, by pressing the Axes button. This sometimes simplifies an otherwise `busy' display. A bargraph in normally present along the right side of the display whenever samples are being analyzed `live' from the A/D converter. It indicates the current number of samples in the input buffer, and therefore whether or not the current analysis parameters and drawing mode are able to keep pace with the A/D sampling rate. If the analysis and display is taking too long, this bargraph will steadily increase over time. When this happens, either the analysis parameters must be changed (e.g. a larger stride), a faster drawing mode must be selected, or the sampling rate must be reduced.
The default drawing mode for the 3D surfaces is Mesh, which created a smooth surface joining all points on the surface. Line mode joins each FFT bin in a spectral slice with line segments. This is much faster to render, hence can be useful at higher A/D sampling rates. Point mode places a single dot on the screen at each bin, according to the magnitude of that bin. Finally, Polygon creates a vertical concave polygonal `plate' for each FFT frame. It requires more time to render than even Mesh mode, but often gives good visual results.
In addition to the normal rectangular display of the time/frequency plane, a polar display mode is implemented. When this mode is selected, via the Polar button, successive spectral frames are displayed radially, like the rotating arm of a radar display, with DC at the origin, and half Nyquist at the outer radius of the arc. This method has the advantage that there is no need to abruptly reset the drawing position once some number of frames have been rendered. Note that the log frequency option works in this mode as well.
At times, the 3D display may be difficult to analyze, either because prominent features in the foreground obscure important features behind them, or because the resulting surface is too cluttered. For this reason (and for drawing FOF frequency trajectories, as described above), a standard two-dimensional display mode has been implemented. When this mode is entered (by clicking the 2D button), the spectrogram is plotted in the conventional way, with time going from left to right, and frequency (or log f) from bottom to top. In this case, amplitude information is based solely on the color (or gray scale value) of each pixel.
The 3D display is performed using a perspective transformation, so that distant objects appear smaller. While this more realistic display is often desirable, in certain instances, for example when trying to compare spectral frames from one to the next, it may be desirable to defeat this transformation. This can be done by clicking on the perspective button. In this mode, zooming in and out will have no effect, since being closer or further away from the surface does nothing without perspective. Note perspective should usually be defeated when doing z-buffering, described next.
In certain cases, for example when in Polar display mode, it may turn out that successive spectral slices are displayed `behind' preceding ones. In this case, the original, closer frames may be incorrectly over-written by the new frames. In order to prevent this a Z-buffer feature has been included, which uses the computer's dedicated z-buffer hardware to determine whether a pixel being rendered into the frame buffer is closer or further away than the pixel already in the frame buffer at that screen location. Based on this z-comparison, the new pixel either replaces the original one, or the original one remains untouched. This feature is activated by clicking the ZB button. Note that, for proper operation of the z-buffer hardware, the perspective transformation should be disabled.
When viewing a small portion of a spectral surface, it may be useful to double-buffer the display, so that the actual redrawing of the surface as it moves around is not seen. Rather, the redrawing is done to a second off-screen frame buffer. Once the entire surface being examined is completely redrawn, this secondary buffer becomes visible, and what was the visible buffer becomes the secondary buffer where the next redraw starts. This makes the overall impression much smoother as the surface is manipulated or reoriented.
While synthesizing from the current STFT surface, it is possible to view the resulting wave form in a spearate window, by clicking the Scope button. In this case, three waveforms are displayed, which indicated the operation of the overlap/add calculation visually. The uppermost is the IFFT of the current frame. The middle wave form shows the accumulation buffer, which contains the shifted data from the previous frame. Finally, the bottom wave form shows the `stride' current samples that are to be sent to the DAC. They are the result of adding the samples from the two traces immediately above. In the case where there is no overlap, the three wave form display is replaced by a single wave form which is the IFFT of the current frame. This frame then gets sent directly to the DAC.
[1] Shipman, D. 1983. "SpireX: Statistical Analysis in the SPIRE Acoustic-Phonetic Workstation." Proc. IEEE International Conference on Acoustics, Speech, and Signal Processing. vol. 3, pp. 1360-1363.
[2] Roads, C. 1983. "A Report on SPIRE: an Interactive Audio Processing Environment." Computer Music Journal, vol. 7(2), pp. 70-74.
[3] Flanagan, J.L. 1972, "Speech Analysis, Synthesis, and Perception". Springer-Verlag, New York.
[4] Allen, J.B. 1977. "Short Term Spectral Analysis, Synthesis, and Modification by Discrete Fourier Transform," IEEE Trans. on Acoust., Speech, and Sig. Proc., vol. ASSP-25(3), pp. 235-238.
[5] Allan, J.B. and Rabiner, L.R. 1977. "A Unified Approach to Short Time Fourier Analysis and Synthesis," Proc. IEEE, vol. 65, pp. 1558-1564.
[6] Harris, F.J. 1978. "On the Use of Windows for Harmonic Analysis with the Discrete Fourier Transform," Proc IEEE, vol. 66, pp. 51-83.
[7] Serra, X. 1989. "A System for Sound Analysis/Transformation/Synthesis Based on a Deterministic Plus Stochastic Decomposition," PhD Dissertation, Department of Music, Stanford University.
[8] Portnoff, M.R. 1980. "Time-Frequency Representation of Digital Signals and Systems Based on Short Time Fourier Analysis," IEEE Trans on ASSP, vol 28(1), pp. 55-69.
[9] Crochiere, R.E. 1980. "A Weighted Overlap-Add Method of Short-Time Fourier Analysis/Synthesis," IEEE Trans on ASSP, vol 28(1), pp. 99-102.
[10] Griffin, D. W. and Lim, J.S. 1984. "Signal Estimation from Modified Short-Time Fourier Transform", IEEE Trans on ASSP, vol 32(2), pp. 236-243.
[11] Dolson, M. 1986. "The Phase Vocoder: A Tutorial". Computer Music Journal, vol. 10(4), pp. 14-27.
[12] Abel, J.S. 1993. Personal correspondence.
[13] Overmars, M. "The FORMS User Interface Manual", available via internet from the author at markov@cs.ruu.nl.
[14] Haykin, S. 1989. "Modern Filters", Macmillan Publishing Co., N.Y., pp. 215-219.
[15] Rodet, X. 1984. "Time Domain Formant Wave Function SYnthesis," Computer Music Journal, vol 10(4), pp. 14-27.