 An Example Application of HTM
An Example Application of HTM
Until recently, general-purpose computers have been too slow to use alone for rapid prototyping of new musical sound synthesis algorithms and control strategies. The tough real-time and arithmetic computational performance demands of computer music applications are usually satisfied by supplementing general-purpose computers with multiple signal processors. Unfortunately, these signal processing systems are expensive and harder to program than their controlling computers.
HTM, the real-time software synthesis system described in this paper, addresses these difficulties by taking advantage of advances in recently introduced superscaler RISC workstations: increased arithmetic computational performance, compiler quality, real-time scheduling and networking performance. HTM may be combined with a rich and extensible music programming environment such as MAX [Puckette 1988,1990] to create a system suitable for both rapid development of experimental research prototypes and live musical performance.
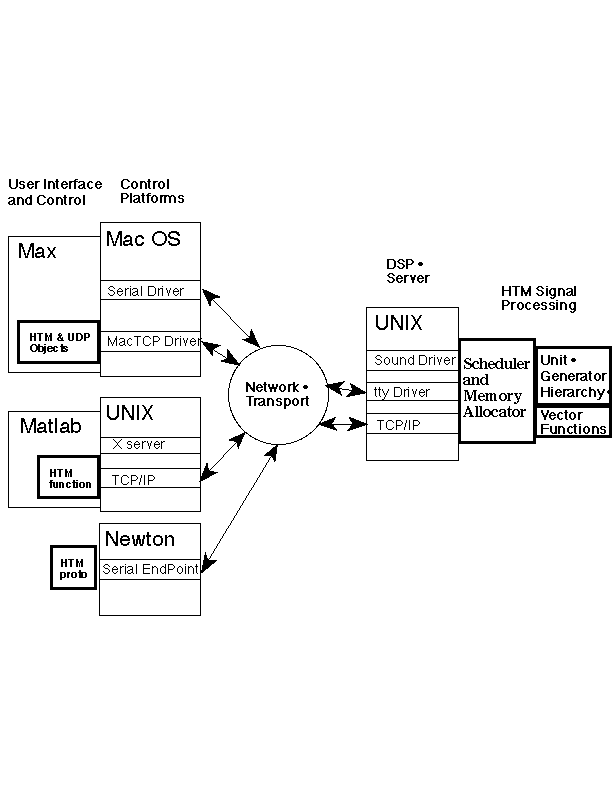
As shown in the figure below, HTM provides sound synthesis and processing services to control and display applications that communicate with it over a network. This client/server architecture was chosen because it scales smoothly from individuals sharing a single machine, through the small ensemble, up to large groups of institutional users, as well as geographically dispersed collaborators.
The UDP protocol from the TCP/IP suite [Comer 1988] was chosen for HTM communications because it is widely available, connectionless and offers low latency performance for small packet sizes. UDP datagrams are also routed through gateways; thereby HTM synthesis servers are accessed as easily within the same building as anywhere in the world, using, for example, the Internet.
An Example Application of HTM
The first implementation of HTM is for the SGI Indigo, a machine with efficient TCP/IP support, good balanced computing performance and excellent built in audio capabilities. The screen snapshot above, from an Indigo, illustrates HTM in use for the development of a real-time implementation of a singing voice synthesis model. Three programs are communicating with an invisible but audible HTM server: a panel of sliders, a 3 dimensional spectral display and a signal graphing application. The display applications monitor signals in any of the published nodes of the synthesis patch. A text editor window contains part of the source code of a unit generator being debugged.
Control, real-time synthesis, display, text editing and compilation activities all function concurrently. The loose coupling afforded by connectionless UDP communications, allows the HTM server to be stopped, recompiled, and rerun without disturbing the surrounding test harness. Concurrency and loose coupling are essential for rapid prototyping of music synthesis applications.
The display and control tools illustrated above have been optimized for the development and exploration of synthesis algorithms. For more sophisticated control strategies required in musical performance, the MAX language can be used with HTM. An enhanced version of a DSP object [Freed and Gordon 1990] for MAX manages communications. This DSP object was originally developed to manage the communication of parameter changes between a host computer and synthesis programs running on target digital signal processors. It consists of both a processor-independent component that manages parameter naming, scaling and integration in the MAX environment, and a processor-dependent component that manages communications with signal processors. This partitioning allows a new component for networked processing resources to be easily added. With the DSP object, MAX users see a high-level, device-independent view of sound synthesis resources as symbolically named processing nodes waiting for named parameter value changes.
The central part of HTM shields synthesis algorithm developers from the details of real-time scheduling, memory allocation, UDP packet reception, transmission, assembly and disassembly, and audio input and output. Developers need only provide an initialization routine, routines to be scheduled to compute samples and routines to process named parameter updates.
Although the HTM server may be easily interfaced to a large software synthesis language such as CMix [Lansky 1990], CMusic [Moore 1990], or CSound [Vercoe 1991], already available on the SGI Indigo, such systems would fail to take advantage of the potential computing performance available. HTM, on the other hand, includes a library of new unit generators and vector functions that are optimized for superscaler RISC processors and multiprocessor architectures.
A complete explanation of the design of the HTM library would require an analysis of modern computer architectures [Hennessey and Patterson 1990] and their supporting software. Although such a comprehensive explanation is beyond the scope of this paper, HTM's principle design element, vector operations, will be discussed here. The use of vector operations is important because it significantly impacts the synthesis algorithm developer.
In the 1970's and 1980's the silicon implementation of multiplication and addition operations was the primary factor limiting processor performance for signal processing algorithms. However, with current levels of circuit integration, processor performance is determined by the rate at which operands can be supplied to arithmetic units. At equal clock rates the peak arithmetic performance of RISC processors and DSP chips from all the vendors differs only by a small factor. The key to obtaining good performance from these processors therefore is to tune the algorithms' data access patterns to the size and timing constraints of the processor's memory hierarchy: its registers, on-chip and off-chip cache and bulk memory.
Musical applications at 44100 samples per second can require hundreds of arithmetic operations per sample. Not all operands and results can be stored in registers and most musical applications regularly access more data than will fit in a processor's on chip data memory. A simple calculation will illustrate how hard it is to sustain arithmetic processing rates close to the vendors published peak performance. Most recent processors can perform overlapped floating point multiply and add operations in a few clock cycles. These require that 4 operands and 2 results be moved to and from the memory hierarchy. This is enough time to get an operand from external memory and perhaps one or two from an on-chip cache or data memory. To keep the arithmetic units busy, remaining operand data movements have to be between registers. Digital Signal Processors facilitate this by hardwiring two of the data movements and creating a single multiply and add to accumulator instruction, and by providing two parallel data memories. RISC processors use register files and pipeline registers that support several concurrent read and write operations per cycle, as well as wide on-chip data caches.
How does the HTM library minimize the number of stalls for operands? First, rather than creating a loop containing calls to unit generators that would each contribute to the computation of a single sound sample, HTM schedules calls to functions that operate on vectors of samples. This allows for commonly used operands to be loaded into registers at the start of a loop and good arithmetic performance in the body of the loop, as described in the next section. Second, operand sizes are minimized where possible. On most processors single precision floating point operations are faster than double precision ones, but a more significant advantage stems from a higher cache hit rate due to more efficient use of cache memory.
The vector approach is an old one. Its application in hardware has produced the array processor and vector processors in supercomputers. Due to the importance of vector and matrix operations in scientific computations, workstation vendors invest heavily in compiler optimizations that reorder operations within loops to exploit instruction-level parallelism and minimize stalls for data [Kastens 1990]. The HTM library is written in ANSI C in a style designed to be readable and to capitalize on these optimizations [Freed 1992].
Advantages of a vector approach, in addition to computational efficiency, include: the availability of libraries of vector functions, UDI for example [Depalle and Rodet 1990]; computational advantages of "fast" algorithms for block transforms [Malvar 1992], e.g., the FFT and FHT; and lower communication overhead in multiprocessor systems. However, three difficulties inherent in the vector approach need to be addressed.
The first difficulty, particularly important in real-time applications, is managing scheduling of calculations to one sample precision when the basic grain size of computations is a vector of samples. A solution to this problem is to dynamically split large vectors into smaller ones when required, taking into account the slight increase in overhead [Rodet and Eckel 1988].
The second difficulty concerns recursive structures. These are found, for example, in IIR filters, tapped delay lines and wave guides. Such structures cannot be readily built from simple multiply, add and delay unit generators because of the inherent vector delay imposed by each. Instead, unit generators have to be specially written for these situations. This is not a difficult constraint as musicians rarely build from elemental unit generators, but it does require that a unit generator library contain implementations of the commonly needed recursive structures.
The third difficulty with vectors is the temptation of introducing an implicit aliasing downsampling of control parameters by sampling and holding parameter values at the start of each vector computation. Sampling a parameter such as the amplitude of an oscillator will readily create audible artifacts. The effect of sampling other parameters such as filter coefficients is much harder to predict analytically and very hard to trace by audition.
Successfully avoiding these artifacts requires the careful application of one of the oldest optimizations in computer music, the k-rate. The k-rate is typically an integer sub multiple of the audio sample rate and is motivated by the observation that the bandwidth of human gestures for synthesis control is usually lower than the audio sample rate. MAX, with its 1 millisecond timing, has been optimized for these k-rate computations. Interpolation during the computation of the vector is required to avoid the effects of aliasing of these control parameters. Therefore, all HTM unit generators interpolate control parameters to the extent necessary to avoid artifacts.
HTM has been used to develop new, real-time implementations of singing voice synthesis [Rodet et al 1984], synthesis by resonances [Barriere et al 1989], additive synthesis [Sandell and Martens 1992], additive synthesis by Inverse FFT [Rodet and Depalle 1992] and for research on non-linear oscillators for modeling excitations of musical instruments [Rodet 1992].
Experiments with guaranteed latency communications using high speed serial RS422 communications, ISDN, Frame Relay and lightly loaded ethernets are underway.
Vendor's integration of standardized real-time facilities into their variants of UNIX will allow for development of a more portable version of HTM.
Development with HTM would be easier if patches could be created and edited dynamically. This requires that HTM be imbedded in an interpreted language such as MAX, Lisp, or Scheme.
Integration of a multiprocessor scheduler [Buck et al 1991] would facilitate the development of a high performance version of HTM for RISC and DSP multiprocessors.
Xavier Rodet developed the Motif graphing and user interface tools shown in the screen snapshot and was the primary early adopter of HTM. Mike Lee added the TCP/IP support to MAX. Roger Powell, Carol Peters and the whole SGI audio group provided equipment and guidance. PacBell and UC Berkeley EECS department provided and supported the Frame Relay link to the Internet.
Barriere, J-B, Baisnee, P-F, Freed, A., Baudot, M-D, 1989, "A Digital Signal Multiprocessor and its Musical Application", Proceedings of the 15th International Computer Music Conference, Ohio State University, CMA, San Francisco, CA.
Buck, J., Ha, S., Lee, E. A., Messerschmitt, D. G., 1991, "Ptolemy: A Platform for Heterogeneous Simulation and Prototyping", Proceedings of the 1991 European Simulation Conference, Copenhagen, Denmark, June 17-19.
Comer, D. E., 1988, "Internetworking with TCP/IP: Principals, Protocols and Architectures", Prentice Hall, Englewood Cliffs, New Jersey.
Depalle, Philippe and Xavier Rodet, 1990, "UDI: A Unified DSP Interface for Sound Signal Analysis and Synthesis", Proceedings of ICMC , Computer Music Association, San Francisco, CA.
Freed, A., Gordon, K., 1990, "DSP Driver Software for Performance-Oriented Music Synthesis Systems", Proceedings of the 16th International Computer Music Conference, Glasgow, 1990, Computer Music Association, San Francisco, CA.
Freed, A., 1992, "Clear, Efficient Musical Signal Processing in ANSI C", CNMAT Internal Report, Berkeley, CA.
Hennessey, J. L. and David A. Patterson, 1990, "Computer Architecture: A Quantitative Approach", Moran Kaufmann, Palo Alto, CA.
Kastens, U., 1990, "Compilation for Instruction Parallel Processors", Proceedings 3rd Compiler Compilers Conference 1990, Springer-Verlag.
Lansky, P., 1990, "CMix Release Notes and Manuals", Department of Music, Princeton University.
Malvar, H. S., 1992, "Signal Processing with Lapped Transforms", Artech House, Norward, MA.
Moore, F.R., 1990, "Elements of Computer Music", Prentice Hall, Englewood Cliffs, NJ.
Puckette, M., 1988, "The Patcher", Proceedings of the 14th International Computer Music Conference, Köln,1988, Feedback Studio Verlag, available from Computer Music Association.
Puckette, M., Zicarelli, D., 1990, "MAX - An Interactive Graphic Programming Environment", Opcode Systems, Menlo Park, CA, 1990.
Rodet, Xavier et al., 1984, "The CHANT Project: From the Synthesis of the Singing Voice to Synthesis in General", Computer Music Journal, 8(3):15-31.
Rodet, Xavier and Gerhard Eckel, 1988, "Dynamic Patches: Implementation and Control in the SUN-Mercury Workstation", Proceedings of the ICMC, 1988, CMA, San Francisco, CA.
Rodet, Xavier, 1992, "Nonlinear Oscillator Models of Musical Instrument Excitation", Proceedings of the ICMC, 1992, CMA, San Francisco, CA.
Rodet, Xavier and Phillippe Depalle, 1992, "Spectral Envelopes and Inverse FFT Synthesis", Proceedings of 1992 AES Convention, AES, New York, NY.
Sandell, Gregory J., and William L. Martens, 1992, "Prototyping and Interpolation for Multiple Musical Timbres Using Principal Component-Based Synthesis", Proceedings of the ICMC, 1992, CMA, San Francisco, CA.
Vercoe, B. 1991, "CSound Manual and Release Notes", MIT Media Laboratory, Cambridge, MA.