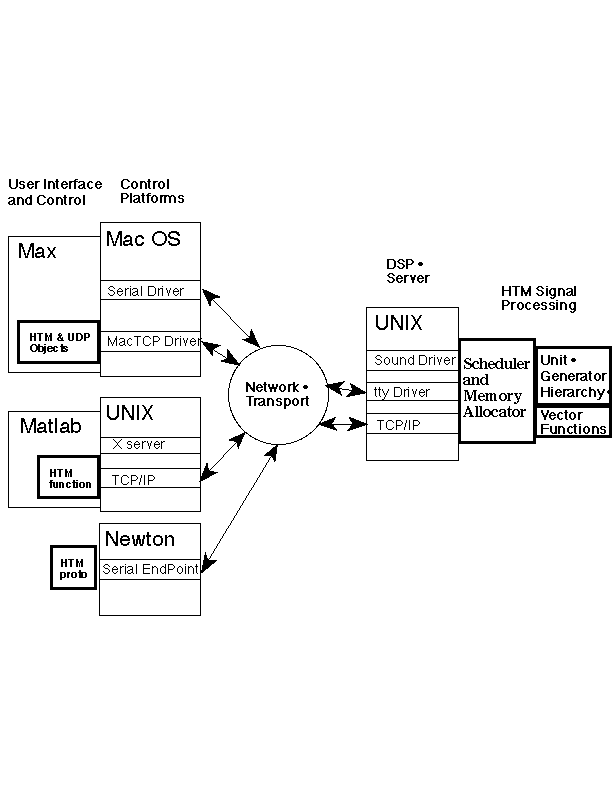
The HTM system supports parallel development of the basic elements of DSP applications: a user interface, control structure and digital signal processing code. User interface and control is central in many new DSP applications, e.g. musical sound synthesis, image processing, multimedia, speech recognition and synthesis.
To facilitate successful collaborative development between a team of specialists, HTM tools:
* support the construction of complete system prototypes that run in real-time at the full (audio) sample rate of the application, and
* allow designers to use tools most productive for and familiar to them regardless of the computing platform the tools require.
Until recently, general-purpose computers have been too slow to use alone for rapid prototyping of DSP algorithms and control strategies. The tough real-time and arithmetic computational performance demands of DSP applications are usually satisfied by supplementing general-purpose computers with multiple signal processors. Unfortunately, these signal processing systems are expensive and harder to program than their controlling computers. The HTM system exploits advances in recently introduced superscaler RISC workstations: increased arithmetic computational performance, compiler quality, real-time scheduling and networking performance.
The HTM system components include:
* a library of stateless signal processing vector functions,
* a library of higher level "unit generators",
* real-time resource allocation functions for the SGI workstation,
* TCP/IP support for Opcode MAX, Matlab, and other Macintosh and UNIX clients,
* a collection of example applications including a singing voice sound synthesizer.
HTM is designed to support development of applications for which real-time interactive performance is essential. Rapid prototyping of signal processing algorithms is not enough. These prototypes have to run efficiently enough on affordable and readily available computing environments to fully implement applications and their real-time requirements. We have concluded that a high level programming language and floating floating point arithmetic are essential in such an environment. We have abandoned a promising, high performance DSP multiprocessor for prototyping and design work because it did not meet these requirements. A set of guidelines for programming signal processing algorithms in an efficient and clear way has been developed for ANSI C [Freed 93]. These guidelines were followed in the development of the signal processing library described below.
In the 1970's and 1980's the silicon implementation of multiplication and addition operations was the primary factor limiting processor performance for signal processing algorithms. However, with current levels of circuit integration, processor performance is determined by the rate at which operands can be supplied to arithmetic units. At equal clock rates, peak arithmetic performance of RISC processors and DSP chips differs little amongst vendors. The key to obtaining good performance from these processors therefore is the tuning of data access patterns to the size and timing constraints of the processor's memory hierarchy: its registers, on-chip and off-chip cache and bulk memory.
Signal processing applications at audio samples rates require hundreds of arithmetic operations per sample. Not all operands and results can be stored in registers and most signal processing applications regularly access more data than will fit in a processor's on chip data memory. A simple calculation will illustrate how hard it is to sustain arithmetic processing rates close to the vendors published peak performance. Most recent processors can perform overlapped floating point multiply and add operations in a few clock cycles. These require that 4 operands and 2 results be moved to and from the memory hierarchy. This is enough time to fetch an operand from external memory and perhaps one or two operands from an on-chip cache or data memory. To keep the arithmetic units busy, remaining operand data movements have to be between registers. Digital Signal Processors facilitate this by hard-wiring two of the data movements and creating a single multiply and add to accumulator instruction, and by providing two parallel data memory banks. RISC processors use register files and pipeline registers that support several concurrent read and write operations per cycle, as well as wide on-chip data caches.
The HTM signal processing library is written to minimize the number of stalls for operands. Instead of functions to compute single samples, HTM schedules calls to functions that operate on vectors of samples. This allows for commonly used operands to be loaded into registers at the start of a loop and good arithmetic performance in the body of the loop, as described in the next section. Operand sizes are minimized where possible. On most processors single precision floating point operations are faster than double precision ones and equally important make more efficient use of cache memory.
The vector approach is not new--ts application in hardware has produced the array processor and vector processors in supercomputers. Due to the importance of vector and matrix operations in scientific computations, workstation vendors invest heavily in compiler optimizations that reorder operations within loops to exploit instruction-level parallelism and minimize stalls for data [Kastens 1990]. The HTM signal processing library is written to take advantage of these optimizations [Freed 1993].
Other advantages of the vector approach include:
* The availability of libraries of vector functions, UDI for example [Depalle & Rodet 1990]
* Computational advantages of "fast" algorithms for block transforms [Malvar 1992], e.g., the FFT and FHT
* Lower communication overhead in multiprocessor systems.
However, three difficulties inherent in the vector approach need to be addressed:
1) Scheduling of calculations to the precision of a single sample is critical in many real-time signal processing problems. This requires special strategies if the basic grain size of computations is a vector of samples. HTM addresses this problem by dynamically splitting large vectors into smaller ones when required, taking into account the slight increase in overhead [Rodet & Eckel 1988].
2) Recursive structures such as IIR filters, tapped delay lines and wave guides cannot be built by composing elemental multiply, add and delay vector functions because of inherent vector delays. Although it is possible to synthesize code for these optimized recursive structures from high level descriptions, we have adopted the pragmatic approach of providing a hand coded library of commonly used high level functions or "unit generators".
3) It is tempting for reasons of efficiency to sample and hold control parameter values at the start of each vector computation. At audio sample rates, for example, such sampling of the amplitude of an oscillator creates audible artifacts. The effect of sampling other parameters such as filter coefficients is hard to predict analytically and very hard to trace by audition. To avoid these aliasing artifacts HTM unit generators interpolate (usually linearly) all control parameters.
With the features described above, the unit generator library efficiently supports the next level in the computational hierarchy: the "control structure." The control structure maps gestures from the user to parameters for the signal processing layer. Timing accuracy for this mapping in the millisecond range suffices and strict synchrony to the signal sampling rate is not required.
Unit generators include: oscillators, filters, filter banks, band-limited pulse generators, neural networks, frequency modulated oscillators, and noise sources.
Unit generators are combined hierarchically into ever higher level unit generators. Signal flows are managed in small memory arrays called "wires". At the top level is a single unit generator with input and output connections to the HTM scheduler, described below. In audio application the input/output wires are connected to the A/D and D/A converters of the workstation.
The HTM user-level scheduler is built on standard scheduling features of UNIX systems: non-degrading process priority, locked memory and grouped I/O semaphores, i.e. the select(2) system call.
The HTM scheduler directs traffic between three entities: control structure parameter updates and requests, unit generators, and A/D and D/A converters. It attempts to provide low latency service to parameter updates and requests whilst constraining the latency between unit generator computations and workstation converters between specified high and low water marks. The techniques used can be readily adapted to most UNIX workstations. However, the good performance we have experienced on SGI workstations depends on this vendor's fast networking implementation and well designed sound driver. These support the HTM scheduler's use of a single select(2) system call to monitor I/O status, thus minimizing relatively expensive context switches.
HTM provides a fast, deterministic memory allocator to support real-time requirements. The allocation routines are passed an ASCII string to associate with every piece of allocated memory. This greatly enhances performance measurements, optimization and debugging. For example, large arrays that are infrequently accessed can be placed in non-cached pages of memory. The decision of where to place memory may be made in one central place, the storage allocator, rather than scattered throughout the application program. This also supports dynamic memory allocation for load balancing on multiprocessors.
We have found it very convenient to probe memory contents in specialized ways. For example, many of the blocks of allocated memory are "wires" containing signal vectors. A simple interface can be built that presents the user with a list of such wires and allows them to choose an appropriate probe. Standard probes include real-time signal and spectrum graphing and ones that write signals to a file for later analysis. These probes can be added while an application is running obviating an edit/compile/rerun cycle.
As shown above, an HTM DSP process serves control and display clients across a network. This client/server architecture was chosen because :
The architecture scales smoothly from individuals sharing a single machine, through the small design team, up to large groups of institutional and potentially geographically dispersed collaborators.
Server/client communications use standard serial connections and connectionless UDP communications with TCP/IP. TCP/IP communications can readily be added to existing programs on most computing platforms.
The UDP protocol from the TCP/IP suite [Comer 1988] was chosen for HTM communications because it is widely available, connectionless and offers low latency performance for small packet sizes. Connectionless protocols are convenient in prototyping environments because they allow for rapid, "live" insertion and removal of software components without disturbing surrounding components of a test harness.
UDP datagrams are also routed through gateways allowing HTM DSP servers to be accessed as easily within a single building as from anywhere in the world, using, for example, the Internet.
Matlab and MAX [Puckette 1988,1990] have proved to be particularly useful for HTM applications. Matlab offers the control specialist a broad range of traditional and newer mathematical methods of control. MAX, which runs on the Apple Macintosh platform, offers a wide range of user interface tools and is unique in offering a parallel real-time visual data flow programming language. Apple Newton MessagePads have also been interfaced to HTM servers using their serial port. We expect to further exploit these device's potential for pen input and wireless connectivity.
HTM has been used for a wide range of academic and commercial applications including: a singing voice synthesis [Rodet et al 1984], resonance synthesis [Barrière et al 1989], a non-linear wave equation simulation, oscillator additive synthesis, additive synthesis by Inverse FFT [Freed et al. 1993b], research on non-linear oscillators for modeling excitations of musical instruments [Rodet 1993], an exploration of the behavior and control of sound synthesized from nonlinear oscillators and the Chua circuit [Mayer-Kress et al. 1993], and tools for auditory interpretation of scientific data [Bargar 1994].
Robin Bargar
Insook Choi
Mark Goldstein
Mike Lee
Dana
Massie
Roger Powell
Ami Radunskaya
Xavier Rodet
Matt Wright
[Barrière et al. 1989] Barrière, J-B, Baisnee, P-F, Freed, A., Baudot, M-D, 1989, A Digital Signal Multiprocessor and its Musical Application, Proceedings of the 15th International Computer Music Conference, Ohio State University, CMA, San Francisco, CA.
[Bargar 1994] Bargar, R., 1994, Personal Communication, NCSA.
[Comer 1988] Comer, D. E., 1988, Internetworking with TCP/IP: Principals, Protocols and Architectures, Prentice Hall, Englewood Cliffs, New Jersey.
[Depalle et al. 1990] Depalle, Philippe and Xavier Rodet, 1990, UDI: A Unified DSP Interface for Sound Signal Analysis and Synthesis, Proceedings of ICMC, Computer Music Association, San Francisco, CA.
[Freed 1992] Freed, A., Tools for Rapid Prototyping of Music Sound Synthesis Algorithms and Control Strategies, Proceedings of the ICMC San Jose, CA, USA, Oct. 1992
[Freed et al. 1993] Freed, A.,Rodet, X. Depalle, P, 1993, Synthesis and Control of Hundreds of Sinusoidal Partials on a Desktop Computer without Custom Hardware, Proceedings of ICSPAT, 1993, DSP Associates, Boston, MA.
[Freed 1993] Freed. A. Guidelines for Signal Processing Applications in C, The C Users Journal, September 1993.
[Kastens 1990] Kastens, U., 1990, Compilation for Instruction Parallel Processors, Proceedings 3rd Compiler Compilers Conference 1990, Springer-Verlag.
[Malvar 1992] Malvar, H. S., 1992, Signal Processing with Lapped Transforms, Artech House, Norward, MA.
[Mayer-Kress et al. 1993] Mayer-Kress, G.; Choi, I.; Weber, N.; Barger, R.; and others, Musical signals from Chua's circuit, IEEE Transactions on Circuits and Systems II: Analog and Digital Signal Processing, Oct. 1993, vol.40, (no.10):688-95.
[Puckette 1988] Puckette, M., 1988, The Patcher, Proceedings of the 14th International Computer Music Conference, Köln,1988, Feedback Studio Verlag, available from Computer Music Association.
[Puckette & Zicarelli 1990] Puckette, M., Zicarelli, D., 1990, MAX - An Interactive Graphic Programming Environment" Opcode Systems, Menlo Park, CA, 1990.
[Rodet 1984] Rodet, Xavier et al., 1984, The CHANT Project: From the Synthesis of the Singing Voice to Synthesis in General, Computer Music Journal, 8(3):15-31.
[Rodet et al. 1988] Rodet, Xavier and Gerhard Eckel, 1988, Dynamic Patches: Implementation and Control in the SUN-Mercury Workstation,Proceedings of the ICMC, 1988, CMA, San Francisco, CA.
[Rodet 1993b] Rodet, X., Models of musical instruments from Chua's circuit with time delay, IEEE Transactions on Circuits and Systems II: Analog and Digital Signal Processing, Oct. 1993, vol.40, (no.10):696-701.