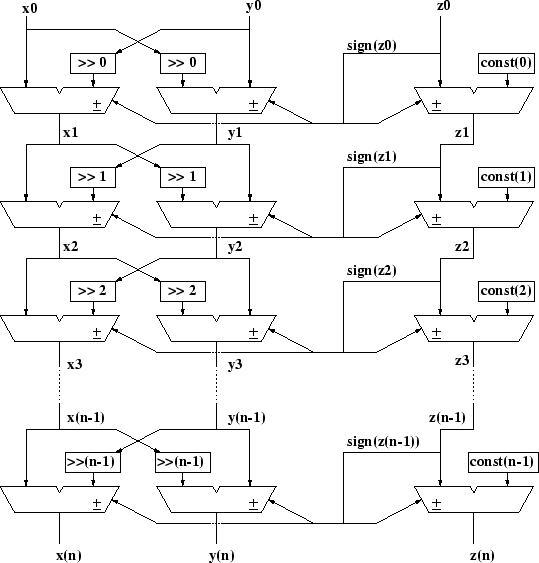
Next: A Bit-Serial Iterative CORDIC Up: Implementation of various CORDIC Previous: A Bit-Parallel Iterative CORDIC
| Center for New Music and Audio Technologies |
|---|
![]()
![]()
![]()
Next: A Bit-Serial Iterative CORDIC
Up: Implementation of various CORDIC
Previous: A Bit-Parallel Iterative CORDIC
|