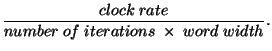|
Center for New Music and Audio Technologies |


Next: Comparison of the Various
Up: Implementation of various CORDIC
Previous: A Bit-Parallel Unrolled CORDIC
A Bit-Serial Iterative CORDIC
Both, the unrolled and the iterative bit-parallel designs, show
disadvantages in terms of complexity and path delays going along with
the large number of cross connections between single stages. To reduce
this complexity one could change the design into a completely bit-serial
iterative architecture. Bit-serial means only one bit is processed at a
time and hence the cross connections become one bit-wide
data paths. Clearly, the throughput becomes a function of
In spite of this the output rate can be almost as high as achieved
with the unrolled design. The reason is the stuctural simplicity of a
bit-serial design and the correspondingly high clock rate
achievable. Figure 1.6 shows the basic architecture
of the bitserial CORDIC processor as implemented in a XILINX Spartan.
Figure 1.6:
Bit-serial CORDIC
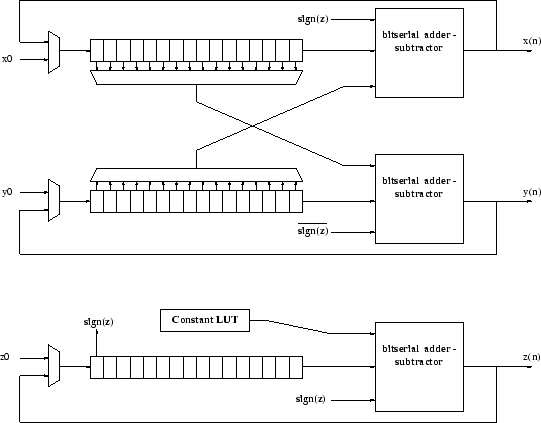 |
In this architecture the bit-serial adder-subtractor component is
implemented as a fulladder where the subtraction is performed by
adding the 2's complement of the actual subtrahent
[13]. The subtraction
is again indicated by the sign bit of the angle accumulator as
described in section 1.2.1. A single bit of state is
stored at the adder to realize the carry chain [14] which
at the same time requires the LSB to be fed in first. The shift-by-i
operation can be realized by reading the bit i-1 from it's right end
in the serial shift registers. A multiplexer can be used to change
position according to the current iteration. The initial values 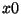 ,
, 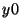 and
and 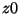 are fed into the array at the left end of the serial-in -
serial-out register and as the data enters the adder component the
multiplexer at the input switch and map back the results of the
bit-serial adder into the registers. The constant LUT for this design
is implemented as a multiplexer with hardwired choices. Finally, when
all iterations are passed the input multiplexers switch again and
initial values enter the bit-serial CORDIC processor as the computed
sine values exit.
are fed into the array at the left end of the serial-in -
serial-out register and as the data enters the adder component the
multiplexer at the input switch and map back the results of the
bit-serial adder into the registers. The constant LUT for this design
is implemented as a multiplexer with hardwired choices. Finally, when
all iterations are passed the input multiplexers switch again and
initial values enter the bit-serial CORDIC processor as the computed
sine values exit.
The design as implemented runs at a much higher speed than the
bit-parallel architectures described earlier and fits easily in a
XILINX SPARTAN device. The reason is the high ratio of sequential
components to combinatorial components. The performance is constrained
by the use of multiplexers for the shift operation and even more for
the constant LUT. The latter could be replaced by a RAM or serial ROM
where values are read by simply incrementing the memory's
address. This would clearly accelerate the performance but since
optimization for one particular FPGA device falls outside the slope of
this paper, we will not consider it further.
Next: Comparison of the Various
Up: Implementation of various CORDIC
Previous: A Bit-Parallel Unrolled CORDIC
Home
Norbert Lindlbauer
2000-01-19